Disclaimer: This is part of my notes on AI research papers. I do this to learn and communicate what I understand. Feel free to comment if you have any suggestion, that would be very much appreciated.
The following post is a comment on the paper Bitnet: Scaling 1 Bit Transformers for Large Language Models by Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fang Yang, Ruiping Wang, Yi Wu, and Furu Wei.
Wang et. al. from Microsoft Research Asia, University of Chinese Academy of Sciences, and Tsinghua University, start what they call the era of 1-bit transformers by introducing BitNet. This project is framed under General AI, whose mission is to advance AI for humanity.
Their work is motivated by the increasing size of LLMs that pose challenges for deployment and raise concerns about the environmental impact due to the high energy coonsumption. A promising solution in these regards are model quantization techniques, where the weights of the models are quantized into set of lower precision. However, most existing quantization approaches for LLMs are post-training, which pose a significant loss in accuracy. The other approach is quantization-aware training, but in general the optimization step becomes more difficult to converge and is not clear whether they scale as good as transformers.
Binarization is the extreme case of quantization. Authors investigate quantizatioin-aware training for 1-bit LLMs, introducing BitNet. In essence, the model employs low-precision binary weights and quantized activations, while maintaining high-precision for the optimizer states and gradients during training.
BitNet
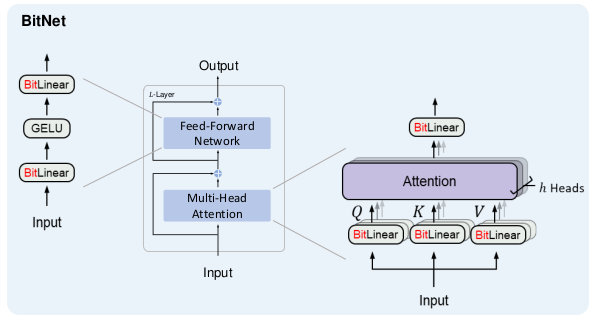
Compared with vanilla Transformer, BitNet uses BitLinear, that uses 1-bit weights, instead of conventional matrix multiplication. The other components of the transformer are left to high-precision (8-bit in this case). Why?
- Residual connections and Layer Normalization costs are negligible
- The computation cost of QKV transformation is much smaller than the parametric projection as the model grows larger
- Input and output need high-precision to perform probability sampling
Therefore, given a transformer we just need to change the nn.Linear layers by BitLinear.
BitLinear
First the weights are centralized to have zero-mean, then binarized to either $+1$ or $-1$ with the Sign function. A scaling $\beta$ factor is used after binarization to reduce the $L_2$ error between the real-valued and the binarized weights.
Besides the weights, the activation layer is also quantized to $b$-bit precision (8-bit in this case). They employ absmax quantization (which scales the activations into the range $[-Q_b, +Q_b]$) and layer normalization to do so.
All this in mind the BitLinear step is formulated as:
\begin{align} y &= \tilde{W}\tilde{x} = \text{Sign}(W - \alpha)\text{Quant}(\text{LN}(x)) \times \frac{\beta \gamma}{Q_b}, \\ \alpha &= \frac{1}{nm}\sum_{i,j}W_{i,j}, \\ \text{Quant}(x) &= \text{Clip}(x \times \frac{Q_b}{\gamma}, -Q_b+\epsilon, Q_b - \epsilon), \\ \text{Clip}(x,a,b) &= \max(a, \min(b,x)), \\ \gamma &= ||x||_\infty, \\ \text{LN}(x) &= \frac{x-E(x)}{\sqrt{\text{Var}(x)+\epsilon}}, \\ \beta &= \frac{1}{nm}||W||_1 \end{align}
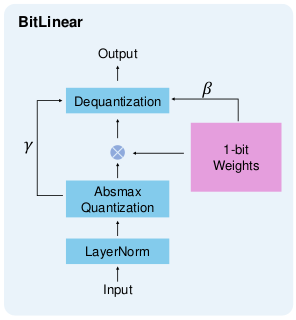
It is important to note that parameters $\alpha, \beta$ and $\gamma$ need the entire tensor making parallelization impossible. To avoid this, Wang et. al. employ group quantization, dividing the weights and activations into groups and then independently estimate each group’s parameters.
Training
Straight-through estimator: To pass the gradient between non differentiable steps (i.e., Sing and Clip) in the backward pass.
Mixed precision training: The gradients and optimizer are stored in high-precision to ensure stability and accuracy. During training there are latent weights in high-precision that accumulate the updates and then are binarized during the forward pass.
Learning rate: Small updates on latent weights do not make any difference in 1-bit weights. They propose increasing the learning rate.
Computational efficiency
There is a huge saving in computational-energy consumption:
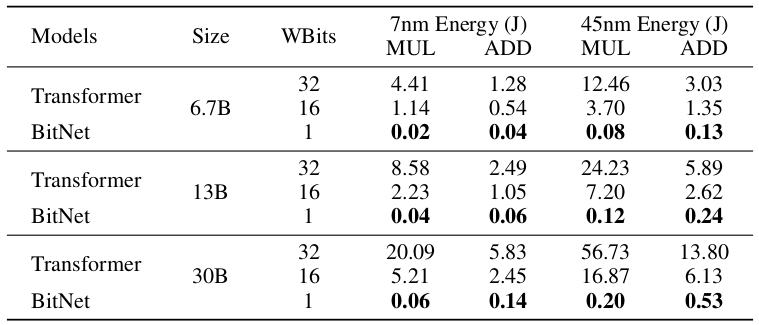
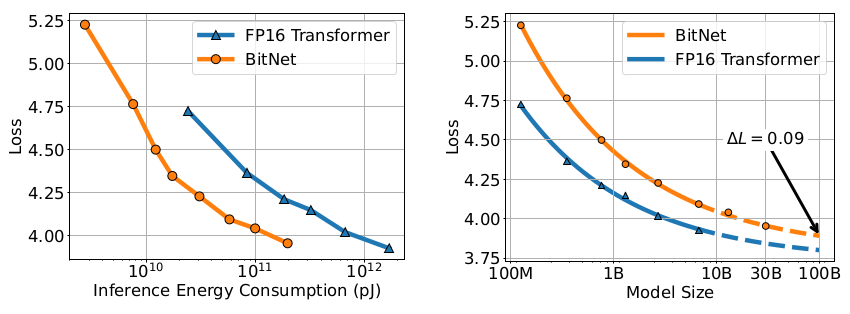
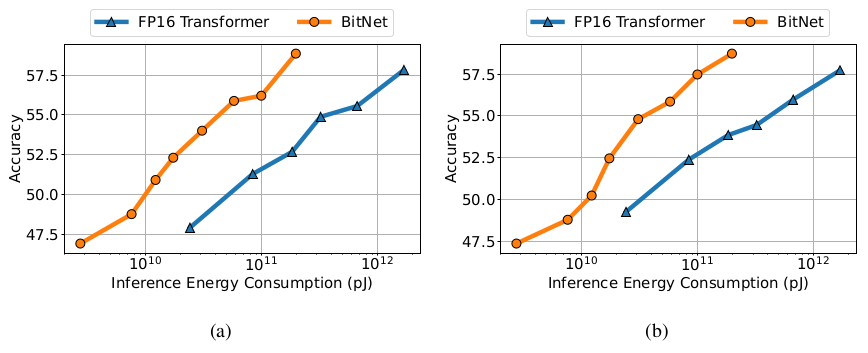
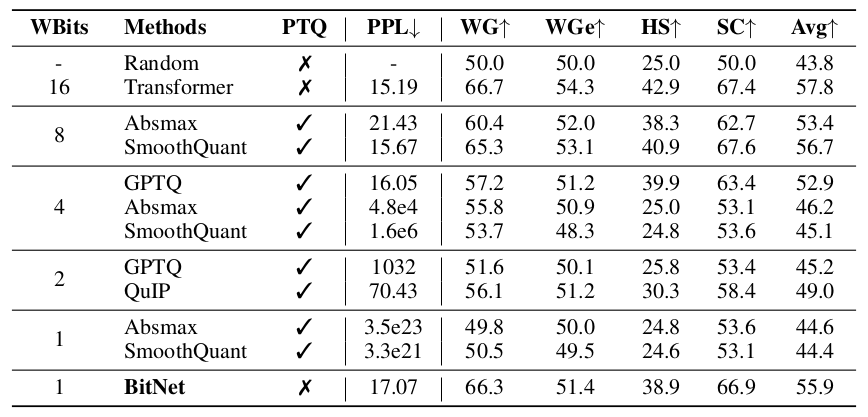
Comparison with Post-training Quantization
The results demonstrate the effectiveness of BitNet in achieving competitive performance levels compared to the baseline approaches, particularly for lower bit levels.
Personal thoughts
Amazing work by GeneralAI team! A promising step to real democratization of LLMs and definitely a must research direction!
Notice that not all the parameters of the model are binarized. This should be further explored and see whether it is feasible or not to binarize everything.
I am wondering, could be possible to also biinarize the tokens? So instead of one-hot encodings they are binary vectors. This should be a richer “token” space that maybe suit well in a 1-bit LLM.
References
[1] Wang, H., Ma, S., Dong, L., Huang, S., Wang, H., Ma, L., Yang, F., Wang, R., Wu, Y., & Wei, F. (2023). Bitnet: Scaling 1 Bit Transformers for Large Language Models. arXiv:2310.11453.